



This chapter describes methods of how to fit data. There are currently five different ways to fit data loaded in the X and Y arrays. Two of these methods fit linear data, one fits gaussians, and two fit polynomials. In addition, only a subset of the data need be fit. Once a fit has been found, the fit may also be plotted. The commands that perform these tasks are described below (and also illustrated in Figure E.9).
The fit command is what is used to do all the fitting of data. The first argument to fit is required and is the type of fit to perform. The first argument must be one of the following values:
There are two different ways to fit linear data: the Least Squares Method and the Method of Least Absolute Deviations. Data that is exponential in form can also be fit with either of these linear methods by first taking the logarithm of the data. There are also two different ways to fit polynomial data. One is a simple polynomial and the other is a fit of Legendre polynomials. In addition to fitting linear and polynomial data, one can also fit gaussians. More than one gaussian curve can be fit simultaneously. Information particular to each type of fitting are discussed below.
In each method, the data from the X and Y arrays will be fit. And, except for the ``medfit'' method, a measure of the error in the Y-direction will be taken from the data in the ERR array. If no data has been previously loaded in the ERR array, then values of unity will be used.
Additionally, each time a fit is performed, information about the fit will be displayed on the command line. The information will contain the fit parameters as well as a measure of the goodness of the fit. Additional (optional) parameters provided to the fit command permit the user to assign these fit terms and their errors to user variables .
The method of Least Squares trys to fit the input data
to a straight line model of the form 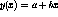 .
This is done by minimizing the chi-squared function:
.
This is done by minimizing the chi-squared function:

where  is the error estimate for each data point (the ERR data).
is the error estimate for each data point (the ERR data).
When a fit is found, this method returns the parameters a and b,
the chi-squared value for the fit, and the probable uncertainties in the
estimates of a and b.
If the data in the ERR array was used to specify the errors on
the observation points (Y array), a ``goodness of fit'' is also returned.
If, however, no errors are specified (there are no points in the ERR
array), then the correlation coefficient (r) is returned
in place of the ``goodness of fit''.
If the ``goodness of fit'' term (represented by the letter `q') is
larger than about 0.1, then the fit is probably reasonable.
Values for the correlation coefficient (r) near 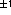 are considered good.
are considered good.
This is similar to the Least Squares Method described above except that the uncertainties in the data (the ERR array data) are ignored and, instead of minimizing the chi-squared function, the merit function to minimize is

The use of the median in this type of fitting provides a more robust method of fitting than the Least Squares method and is especially useful when the data contains outlying points.
When a fit is found, this method returns the parameters a and b and a measure of the mean absolute deviation (in y) of the data points from the fitted line.
A simple polynomial has the form:

where 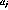 is the jth coefficient of a polynomial of degree N.
The method used to find a fit is just a generalization of the Least
Squares method extended to include more than two coefficients.
is the jth coefficient of a polynomial of degree N.
The method used to find a fit is just a generalization of the Least
Squares method extended to include more than two coefficients.
When a fit is found, this method returns the N coefficients and then the N probable uncertainties in the estimates of the coefficients. Finally, the chi-squared value of the fit is returned.
The method is identical to the Simple Polynomial Fit except that it uses Legendre Polynomials. Legendre Polynomials have the following recurrence relation:
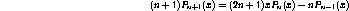
where 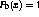 and
and 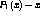 .
.
When a fit is found, this method returns the N Legendre coefficients and then the N probable uncertainties in the estimates of the coefficients. Finally, the chi-squared value of the fit is returned.
This method tries to fit one or more Gaussians to the data. In addition to the style (which must be ``gaussian''), the number of Gaussians to fit must be supplied. Additional parameters may also be supplied to help the fitting routine. For each Gaussian fit, there are three parameters used to describe it: the amplitude, the X-peak position, and the full width at half the peak amplitude (FWHM). Or as an equation:

where 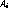 is the amplitude of the ith Gaussian;
is the amplitude of the ith Gaussian;
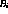 , the peak position;
and
, the peak position;
and 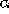 , the FWHM.
The resulting curve will be the sum of the N Gaussians:
, the FWHM.
The resulting curve will be the sum of the N Gaussians:

Note that if any of the supplied Gaussian terms are negative, they will be held fixed during the fitting.
When a fit is found, this method returns three coefficients for each Gaussian fit and the chi-square value of the fit.
There will be some data sets that should only have a subset fit. This could be done by limiting the amount of data loaded into WIP. But that is cumbersome at the least and error prone. The range command allows a portion of the data to be selected and subsequent fitting will only pertain to this subset. The range command can limit data in the X-axis direction only or both the X and Y-axis directions. If the range arguments in either direction are equal, then the range is set as unlimited. Examples of how to use this command are shown in Figure E.9.
The plotfit command
provides an easy way to display the results of a fit.
With no arguments, the fit is displayed over the entire X-axis range.
The first two optional arguments provide a way to limit the X-axis
extent of the displayed fit.
The third argument is an optional step size.
This permits a way to display the fit with finer or coarser resolution.
By default, the command will use the data in the X array
to guess a reasonable step size.
Figure E.9 provides an example of how this command is used.